
One GPU, one epoch, three evaluation surprises, and recall that jumped from 4% to 51%. If you want the concepts behind the decisions (LoRA, QLoRA, NF4, batch size, loss curves), read the companion reference: Every Concept You Need Before Fine-Tuning an LLM.
I work with LLMs daily through APIs and orchestration pipelines. But there’s a difference between using models and understanding what happens inside them. I wanted to get hands-on with the training process itself — so I picked a domain I know well (code security), grabbed a public dataset, and fine-tuned Google’s Gemma 4 E4B on a Colab A100 over a weekend. Code vulnerability detection is the vehicle here, not the destination — every technique applies to any domain. That said, there’s a practical angle: a fine-tuned local model can analyze code without sending it to a cloud API. For teams working on proprietary codebases, air-gapped environments, or regulated industries where code cannot leave the network, a local model — even a modest one — fills a niche that commercial cloud scanners can’t.
The setup
Model: Google’s Gemma 4 E4B — a dense model with 8 billion total parameters and ~4.5 billion effective parameters during inference. The “E” stands for “Effective” — the model uses Per-Layer Embeddings (PLE), where large embedding lookup tables add to the total parameter count but aren’t used in the forward computation, so the effective compute footprint is much smaller than the total (source: Google model card). Instruction-tuned and multimodal (text, vision, audio).
Dataset: DiverseVul — ~330,000 C/C++ functions labeled as vulnerable or safe, spanning 150 CWE categories.
Tool: Unsloth — handles QLoRA loading, optimized training, and GGUF export.
Hardware: Google Colab with an A100 GPU (40GB VRAM). I initially tried a free-tier T4 (16GB) but hit out-of-memory errors during training even with QLoRA and batch size of 1. The A100’s 40GB gives comfortable headroom for QLoRA fine-tuning and supports bf16 precision (more numerically stable than the T4’s fp16).
The dataset
DiverseVul is extracted from vulnerability-fixing commits on GitHub — projects like the Linux kernel, OpenSSL, FFmpeg, and ImageMagick. Each function is labeled vulnerable (1) or safe (0). Note: the dataset is C/C++ only — a different profile from the JavaScript/Python/TypeScript vibe-coded apps mentioned above, but the fine-tuning process is identical regardless of language.
Two properties matter:
It’s heavily imbalanced. ~95% safe, ~5% vulnerable. Training on this raw teaches the model to always say “SAFE” and achieve 95% accuracy while catching nothing. Fix: balanced sampling — I took 3,000 vulnerable and 3,000 safe functions for training, 500 + 500 for validation.
raw = load_dataset("bstee615/diversevul")
vuln = [r for r in raw["train"] if r["target"] == 1 and 30 < len(r["func"]) < 3200]
safe = [r for r in raw["train"] if r["target"] == 0 and 30 < len(r["func"]) < 3200]
train_balanced = random.sample(vuln, 3000) + random.sample(safe, 3000)
The labels are noisy. The DiverseVul authors themselves report 60% label accuracy for vulnerable functions, measured by manually verifying a random sample of 50 (Table 8, DiverseVul paper, RAID 2023). The main sources of error: vulnerabilities spread across multiple functions, and non-vulnerable functions changed in the same commit as the fix. This puts a hard ceiling on achievable performance. For a learning experiment, this is acceptable. For production, you’d invest heavily in label quality first.
Each sample is formatted as a Gemma 4 chat conversation for SFT:
text = (
f"<start_of_turn>system\n{SYSTEM}<end_of_turn>\n"
f"<start_of_turn>user\n{user_msg}<end_of_turn>\n"
f"<start_of_turn>model\n{reply}<end_of_turn>\n"
)
Training
CONFIG = dict(
model = "google/gemma-4-E4B-it",
max_seq_len = 512,
lora_rank = 16,
epochs = 1,
batch_size = 8,
grad_accum = 1, # effective batch = 8
lr = 2e-4,
samples_per_class = 3000, # 3k vuln + 3k safe = 6k total
)
LoRA adapters targeted all attention and MLP layers (q/k/v/o projections, gate/up/down projections). After loading:
GPU: NVIDIA A100-SXM4-40GB
VRAM after model load: ~3.2 / 40.0 GB
Trainable: 42,401,792 / 8,038,558,240 (0.53%)
Training completed in approximately 1 hour 45 minutes on the A100 for one epoch.
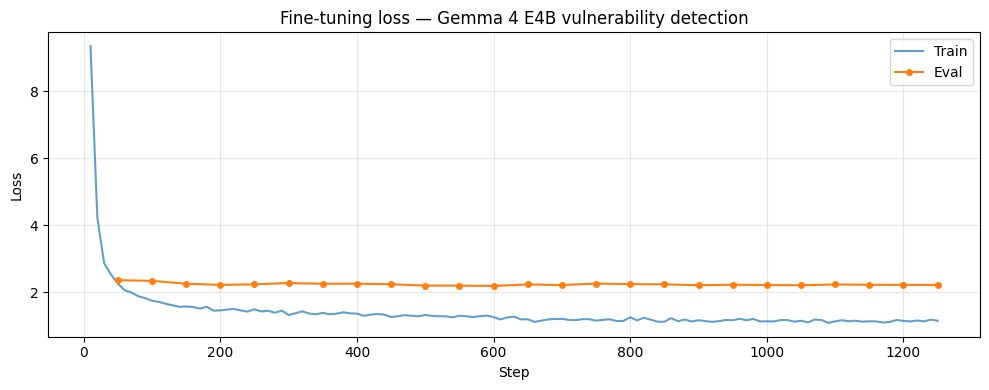 Fine-tuning loss curve. Training loss (blue) drops sharply from ~9.5 to ~1.3. Validation loss (orange) plateaus at ~2.3.
Fine-tuning loss curve. Training loss (blue) drops sharply from ~9.5 to ~1.3. Validation loss (orange) plateaus at ~2.3.
Training loss dropped sharply from ~9.5 to ~1.3 in the first 100 steps. (A starting loss of ~9.5 is higher than typical text models — this is normal for Gemma 4’s multimodal architecture with its large vocabulary. The model hasn’t seen our task format before, so early predictions are essentially random across the full token space.) It continued declining gradually after that.
Validation loss dropped to ~2.3 and plateaued completely. Additional training steps reduced training loss but didn’t improve generalization. I had originally configured 3 epochs, but the validation curve made the decision clear: stop at 1 epoch. The model absorbed the clean, obvious patterns quickly. Further training was fitting the noisy labels, not learning new patterns.
 Unsloth training progress — step-by-step loss showing the plateau during epoch 1.
Unsloth training progress — step-by-step loss showing the plateau during epoch 1.
 Three output formats saved to Google Drive — LoRA adapter, merged SafeTensors, and GGUF.
Three output formats saved to Google Drive — LoRA adapter, merged SafeTensors, and GGUF.
The fine-tuned model is saved in three formats…
Evaluation: three iterations to honest numbers
Evaluating this model correctly turned out to be harder than training it.
The accuracy trap
First run on 200 random test samples: 94.5% accuracy. Impressive — until you check the distribution. 195 safe, 5 vulnerable. The raw test set mirrors the original dataset’s 95/5 imbalance. The model said “SAFE” almost every time and scored well by default.
Lesson: always evaluate on a balanced test set. Accuracy on imbalanced data is meaningless.
The prompt echo
Balanced evaluation (100 vulnerable + 100 safe): 52.5% accuracy, 7% recall. Something was clearly wrong. I looked at the actual model outputs:
CWE: CWE-416
Model said: SAFE and a brief reason.
CWE: CWE-20, CWE-787
Model said: SAFE and a brief reason.
The model wasn’t analyzing code — it was echoing the prompt. The training data used the phrase “Reply with VULNERABLE or SAFE and a brief reason.” At inference time, the model encountered this substring and completed the most probable next tokens — which were the rest of the training template. This is a generation artifact: the model had learned the task, but the decoding followed a memorized path instead of producing new analysis.
The fix was simple: change the prompt wording at inference so it couldn’t trigger the memorized completion. Same model, same weights, different question:
# Triggered memorized template completion
"Reply with VULNERABLE or SAFE and a brief reason."
# Fixed — new wording, model produces actual analysis
"Is it VULNERABLE or SAFE? Explain your reasoning."
The model immediately started producing real analysis:
CWE: unknown
Model: This function is VULNERABLE. The function uses fork() to
execute a command in a child process...
CWE: CWE-190
Model: VULNERABLE. The function TIFFReadRawStrip1 is vulnerable
to a buffer overflow when reading raw data from a TIFF file...
Lesson: fine-tuning teaches a conversational pattern, not just a task. The inference prompt must align with — but not exactly match — the training format. If the prompt contains a substring from training targets, the model may complete the template rather than reason about the input.
The real numbers
Balanced evaluation, 200 samples (100 vulnerable + 100 safe), corrected prompt, with random.seed(42) for reproducibility. Both the fine-tuned and zero-shot models were evaluated with the identical prompt and the same 200 samples for a fair comparison:
| Fine-tuned | Zero-shot (no training) | Delta | |
|---|---|---|---|
| Accuracy | 61.0% | 45.5% | +15.5% |
| Precision | 63.7% | 23.5% | +40.2% |
| Recall | 51.0% | 4.0% | +47.0% |
| F1 | 0.567 | 0.068 | +0.499 |
The base Gemma 4 E4B caught 4 out of 100 vulnerabilities zero-shot — essentially guessing. The fine-tuned version caught 51, bringing recall from near-zero to about half. Not perfect, but a clear signal that the fine-tuning worked, especially given the noisy labels in the training data.
What did fine-tuning actually change?
Here’s what’s counterintuitive: we didn’t teach Gemma 4 about vulnerabilities. It already knew. The model was pre-trained on code, security advisories, CWE descriptions, and countless discussions about buffer overflows and injection attacks. The zero-shot baseline proved this — it sometimes gave detailed, correct explanations of why code was dangerous.
But it only caught 4 out of 100 vulnerabilities in our eval. Why?
Because our eval looked for the word “VULNERABLE” in the response. The base model would say things like “this code has potential security implications that warrant further review” — technically correct analysis, but our parser reads that as SAFE because it doesn’t contain the keyword. A smarter parser that also caught phrases like “security flaw” or “dangerous” would have narrowed the gap — but the inconsistency and lack of structured verdicts would remain. The model knew the answer but expressed it in a way our system couldn’t reliably use.
Fine-tuning was essentially response format alignment — teaching the model to package what it already knew into the structured output we needed:
- Lead with a verdict — always say VULNERABLE or SAFE first, not a hedged paragraph
- Be consistent — same format every time, not sometimes three paragraphs and sometimes one word
- Commit to a decision — no “this could potentially be problematic” — yes or no
Think of it as a senior security consultant who knows everything about vulnerabilities but has never used your team’s reporting template. They can write a brilliant analysis, but they can’t fill in the “Severity: HIGH/MEDIUM/LOW” field consistently. Fine-tuning taught the consultant to use the template.
This is an important insight for anyone considering fine-tuning: if the base model already understands your domain, you may not need thousands of examples to teach it new knowledge. You need enough examples to teach it your expected response structure. In our case, one epoch was sufficient — the model learned the format fast, because the underlying knowledge was already there.
What it catches and what it misses
Running the fine-tuned model against 200 vulnerable test samples grouped by CWE reveals a clear pattern. A caveat: sample sizes per CWE are small (some have only 4 samples), so these recall numbers are indicative of trends, not statistically robust benchmarks.
Strong performers (>60% recall):
| CWE | Description | Caught | Total | Recall |
|---|---|---|---|---|
| CWE-310 | Cryptographic issues | 3 | 4 | 75.0% |
| CWE-20 | Input validation | 12 | 17 | 70.6% |
| CWE-200 | Information exposure | 4 | 6 | 66.7% |
| CWE-787 | Out-of-bounds write | 16 | 25 | 64.0% |
Weak spots (<35% recall):
| CWE | Description | Caught | Total | Recall |
|---|---|---|---|---|
| CWE-415 | Double free | 0 | 4 | 0.0% |
| CWE-401 | Memory leak | 1 | 4 | 25.0% |
| CWE-399 | Resource management | 1 | 4 | 25.0% |
| CWE-416 | Use after free | 4 | 12 | 33.3% |
The model catches vulnerabilities with obvious, localized code signatures — unchecked inputs, buffer writes without bounds checking, weak crypto usage. These are patterns where a single line or function call is the red flag.
Where it struggles is with state-tracking bugs — double frees, use-after-free, memory leaks. These vulnerabilities require understanding execution flow across multiple lines: memory was allocated here, freed there, and then accessed again somewhere else. A model looking at a single function in isolation has limited ability to track that kind of stateful reasoning.
Fine-tuning taught the model to recognize vulnerability signatures, not to perform deep program analysis. True flow-sensitive analysis would likely require either a much larger model, a multi-file context approach, or combining the LLM with static analysis tools — for example, using Semgrep or CodeQL to identify candidate functions, then the LLM to classify and explain. That hybrid approach is worth exploring in a future post.
Key takeaways
Watch the validation loss, not the training loss. Training loss always keeps dropping — that’s memorization. Validation loss tells you when to stop. Mine plateaued halfway through epoch 1.
Evaluation is harder than training. My reported accuracy changed from 94.5% to 52.5% to 61% across three iterations. Each time, the problem was measurement, not the model.
Prompt alignment matters more than you’d expect. The model learned fine — but the inference prompt triggered a memorized template completion instead of actual analysis. Changing the prompt wording fixed it instantly, with no retraining.
Data quality is the ceiling. With ~60% label accuracy (DiverseVul, RAID 2023), no training configuration will produce great results. For production, invest in labels first. For learning, noisy data teaches you the process just as well.
Practical note: if you’re training on Google Colab, save to Google Drive early and often. I lost a full training run when the session disconnected. Mount Drive at the start and set your output directory there.
The outputs
The fine-tuned model is saved in three formats: a LoRA adapter (~160MB), a merged 16-bit SafeTensors model (~8GB), and a GGUF Q4_K_M file (~2.5GB). The evaluation in this post was done on the SafeTensors LoRA checkpoint. The GGUF version hasn’t been evaluated yet — that’s the focus of the next post.
What’s next
In the next post, I’ll take the GGUF file and benchmark different quantization levels — Q4 vs Q5 vs Q8 — measuring what you lose when you shrink a model from 8GB to 2.5GB. Does Q4 still catch the buffer overflows that Q8 catches? Where exactly is the quality cliff?
The code for the full experiment: https://github.com/Geo-Joy/llm-vuln-detector
This is Part 1 of “The Security Engineer’s Practical Guide to LLMs.” Concepts reference: Every Concept You Need Before Fine-Tuning an LLM. Next: What you lose when you shrink a model 4x.