
Part 1 of 2 — The theory and the experiment design. Part 2 shows what actually happened.
When Meta released TRIBE v2 in March 2026, I couldn’t stop thinking about what it could mean for scam detection. This is me finally running the experiment. It’s a personal research project, not a peer-reviewed study — the goal is to ask interesting questions with a new tool and share what comes out. Some findings will hold up under scrutiny; others will invite challenge. Both outcomes are useful. If something here sparks a question, a doubt, or a better experiment — that’s exactly the point.
What if you could watch, in real time, what a scam message does to someone’s brain? Not metaphorically. Not “it activates fear.” I mean a high-resolution map of 29,000 brain regions lighting up as someone reads “Your account has been compromised — verify immediately” — and then see a completely different pattern when they see that same message pop up as a WhatsApp notification on their phone.
That’s now possible. Meta FAIR released TRIBE v2 in March 2026 — a foundation model that takes text, audio, or video as input and predicts how a human brain would respond to it, outputting full fMRI-resolution brain activation maps. It’s designed for neuroscience research: running virtual brain experiments without putting anyone in a scanner.
But I work in scam detection. And the moment I saw this model, I had two questions: do scam messages produce a measurably different brain signature than legitimate ones? And does a scam hack your brain through what it says — or through how it looks?
If the answer is yes, that changes how we think about detecting scams entirely.
What TRIBE v2 actually does
TRIBE v2 is a brain encoding model. You feed it a stimulus — a video clip, an audio recording, or a text passage — and it predicts how the average human brain would respond, across approximately 20,484 cortical surface points (the brain’s outer layer) and 8,802 subcortical voxels (deep brain structures below the cortex).
The architecture is a three-stage pipeline. Three frozen foundation models handle feature extraction: LLaMA 3.2-3B (Meta’s language AI) processes text, V-JEPA2 ViT-Giant (Meta’s video and image AI) processes video and images, and Wav2Vec-BERT 2.0 (an audio understanding AI) processes audio. Each modality’s features get compressed into a shared 384-dimensional space, concatenated into a 1,152-dimensional multimodal time series, and fed into a Transformer encoder with 8 layers and 8 attention heads operating over a 100-second context window. A final prediction head maps these representations onto the brain surface.
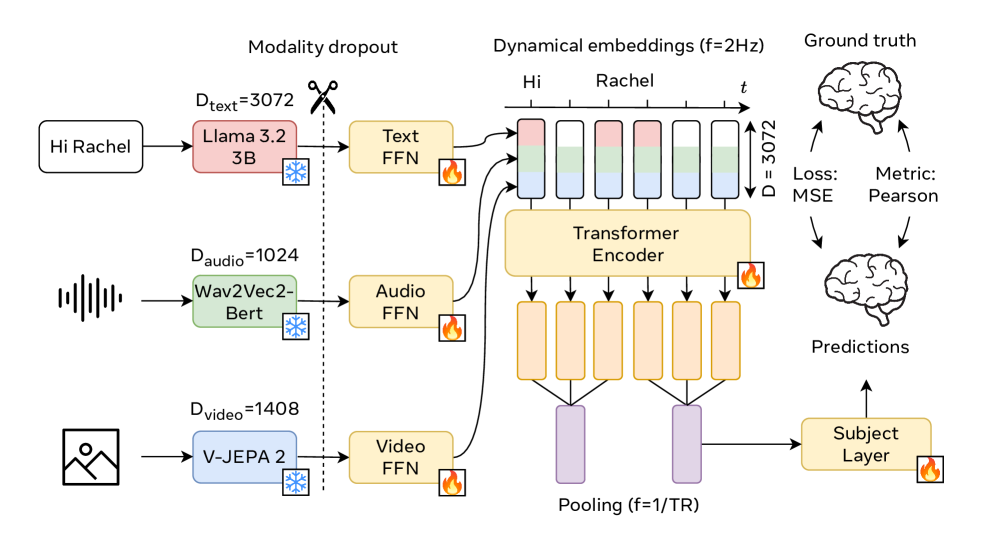 Figure: TRIBE v2 architecture overview. Text, audio, and video inputs are processed by specialized encoders (LLaMA, Wav2Vec-BERT, V-JEPA2), fused into a shared representation, and transformed into predicted fMRI brain activation maps. Source: Meta AI Research.
Figure: TRIBE v2 architecture overview. Text, audio, and video inputs are processed by specialized encoders (LLaMA, Wav2Vec-BERT, V-JEPA2), fused into a shared representation, and transformed into predicted fMRI brain activation maps. Source: Meta AI Research.
The model was trained on 451.6 hours of fMRI data from 25 subjects. Its predictions of group-averaged brain responses are often more accurate than any individual subject’s actual fMRI recording. When researchers applied Independent Component Analysis (a technique for finding hidden structure in data) to the model’s final layer, it had independently discovered five canonical functional brain networks — without being told they exist.
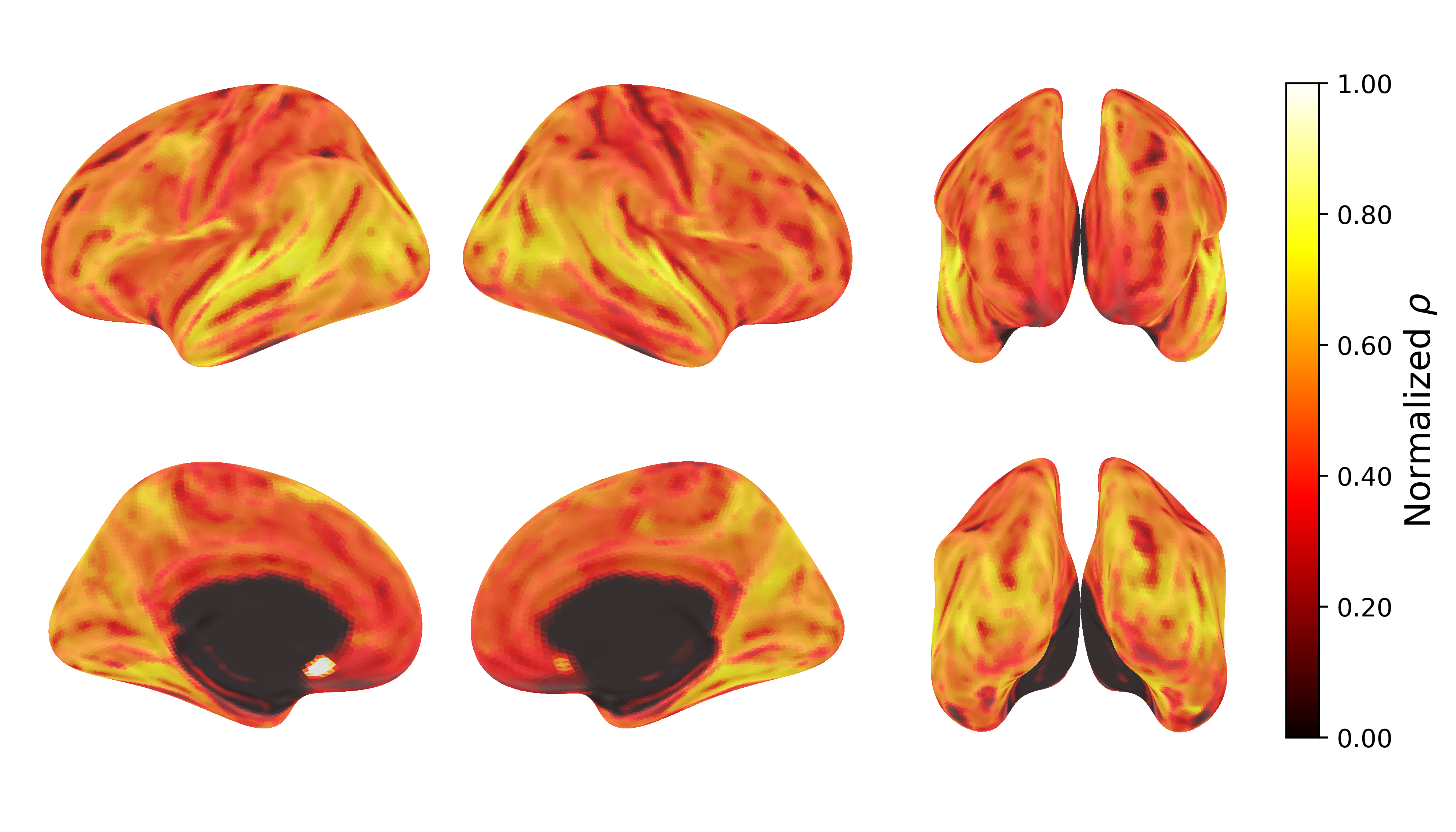 Figure: TRIBE v2 prediction accuracy across the cortical surface. The model achieves strong correlation with actual fMRI data across most brain regions. Source: Meta AI Research.
Figure: TRIBE v2 prediction accuracy across the cortical surface. The model achieves strong correlation with actual fMRI data across most brain regions. Source: Meta AI Research.
The code and weights are open-source on GitHub and HuggingFace under CC BY-NC 4.0.
The neuroscience of deception: why this matters for scams
Here’s the foundational insight: lying is neurologically expensive.
Decades of fMRI research — most notably by Daniel Langleben at UPenn — shows that deception activates the brain very differently from truthful communication. Truth-telling is the brain’s default mode. It requires one cognitive operation: recall and report. Deception demands four simultaneous processes running in parallel:
- Suppress the truthful response (prefrontal cortex)
- Construct a false narrative (dorsolateral prefrontal cortex)
- Monitor internal consistency — does this lie contradict my earlier lies? (anterior cingulate cortex)
- Predict the listener’s response — will they buy it? (temporo-parietal junction)
This asymmetry is measurable, and it leaves fingerprints in the text itself. Studies published in Nature Scientific Reports show that deceptive text contains fewer self-references, more negative emotion words, reduced verifiable details, increased hedging, and inconsistent sentiment patterns. NLP algorithms (text analysis software) trained on these features achieve 77% detection accuracy — far exceeding trained human experts at 59%.
But here’s what gets interesting for scam detection specifically. Scams aren’t just deceptive. They’re engineered to hijack specific neural circuits:
- Phishing messages target the amygdala (threat detection) and anterior cingulate (urgency/conflict monitoring) — “Your account has been compromised” triggers fear before your prefrontal cortex can apply rational evaluation.
- Investment scams target the nucleus accumbens (reward anticipation) — “500% returns guaranteed” activates the same dopaminergic pathways (dopamine reward circuits) as gambling.
- Fake shops exploit the prefrontal cortex (value computation, cognitive evaluation) — “90% OFF today only” creates a perceived value gap that overrides skepticism. The specific prefrontal subdivision — vmPFC (value) vs dlPFC (conflict resolution) — is something the experiment will disambiguate.
- Pyramid schemes are the hardest to detect because they mimic legitimate business opportunity language — the brain activation pattern may be genuinely close to how you’d process a real business proposition.
If TRIBE v2 can predict these differential activation patterns from text and from the visual presentation of the message, we have something no scam detection system currently uses: a measure of how hard a message is trying to hack your brain — and through which channel.
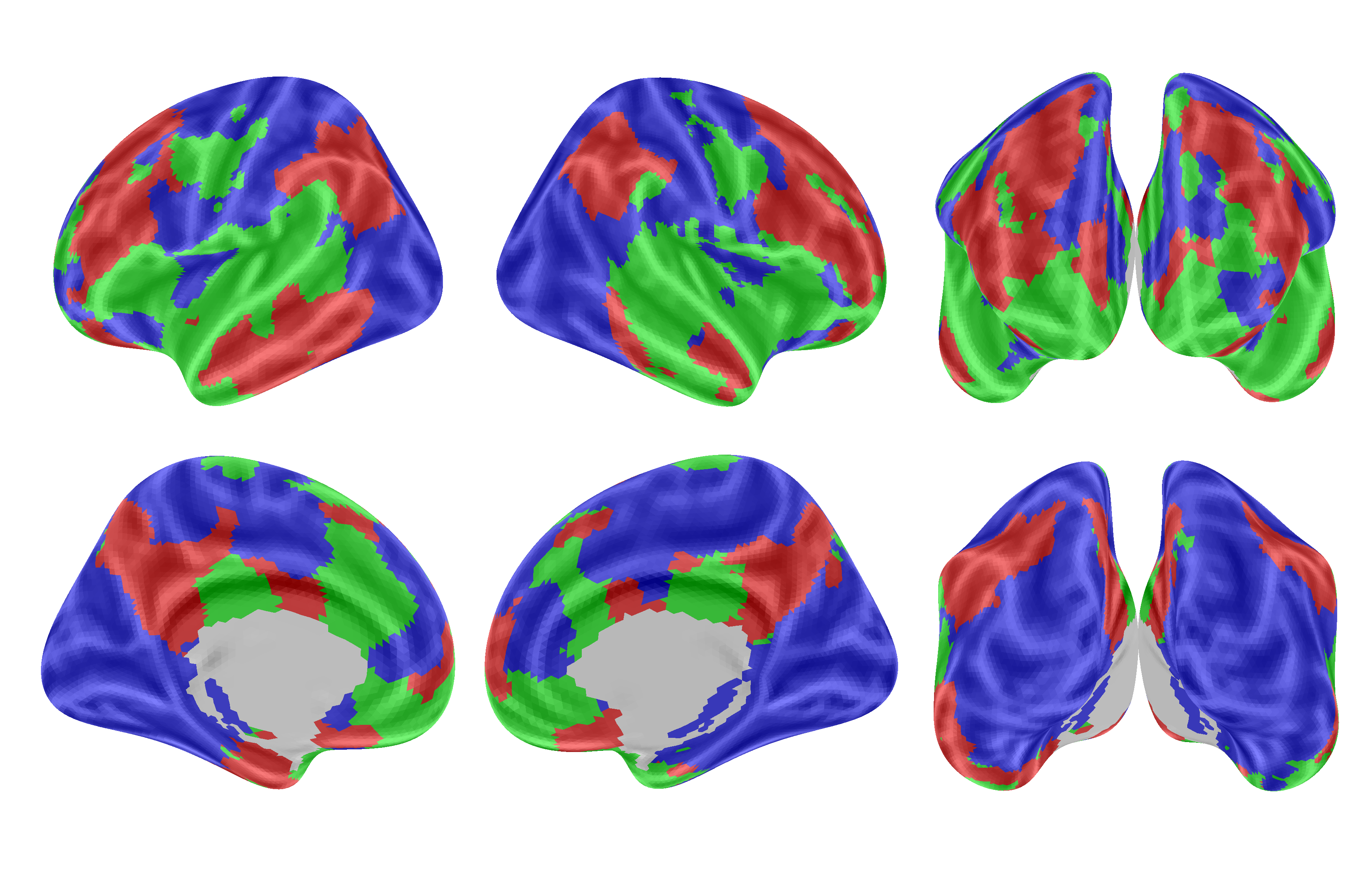 Figure: Which brain regions respond most to each modality in TRIBE v2. Red = video-dominant, Green = audio-dominant, Blue = text-dominant. Note how language processing areas (blue) are distinct from visual cortex (red). This separation enables our text-vs-screenshot experiment. Source: Meta AI Research.
Figure: Which brain regions respond most to each modality in TRIBE v2. Red = video-dominant, Green = audio-dominant, Blue = text-dominant. Note how language processing areas (blue) are distinct from visual cortex (red). This separation enables our text-vs-screenshot experiment. Source: Meta AI Research.
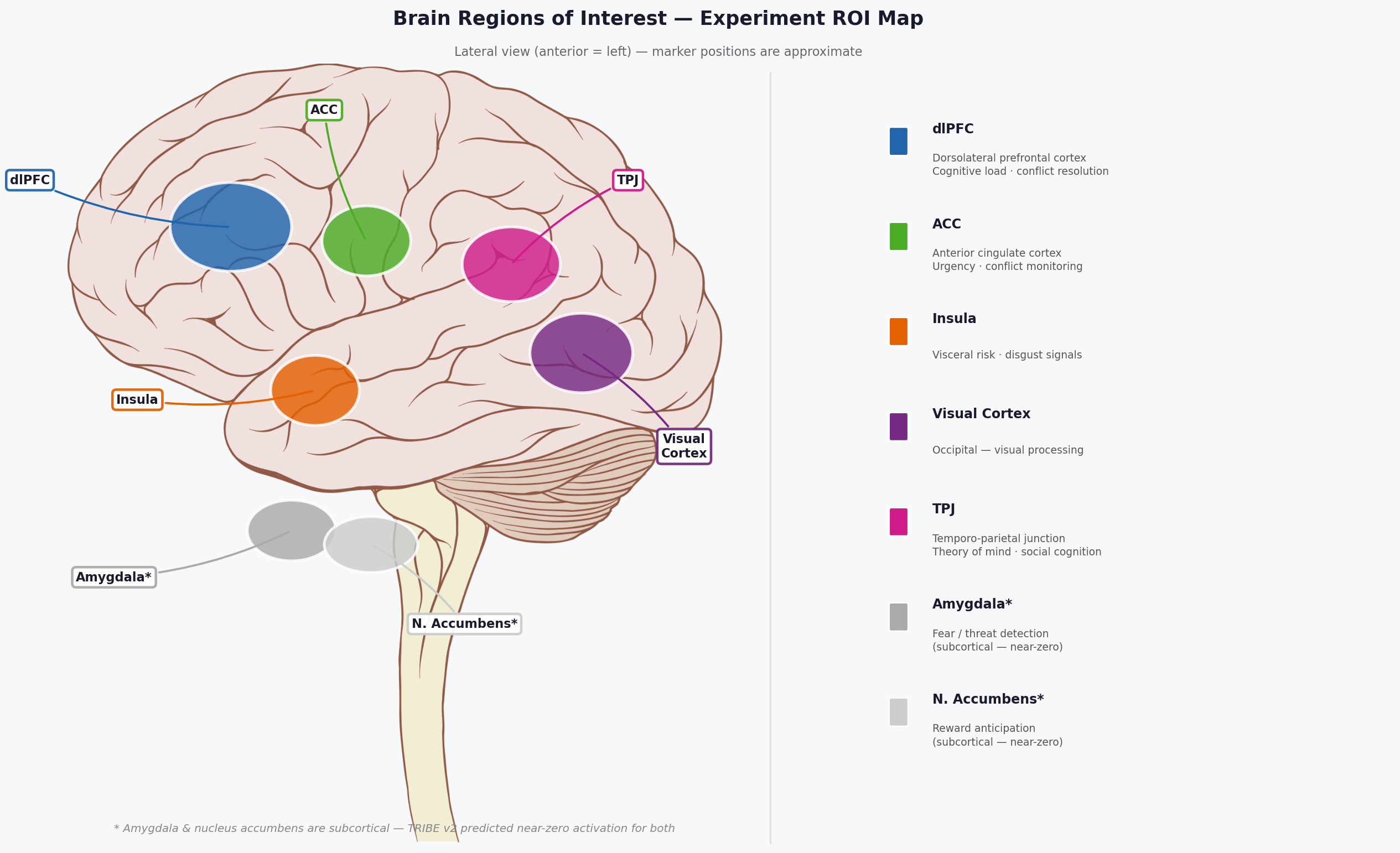 Figure 3: The seven brain regions tracked in this experiment, shown on a schematic lateral view. Blue = dlPFC (cognitive load). Green = ACC (urgency/conflict). Orange = insula (visceral risk). Purple = visual cortex. Pink = TPJ (social cognition). Grey = amygdala and nucleus accumbens (subcortical — near-zero in TRIBE v2’s cortex-focused predictions).
Figure 3: The seven brain regions tracked in this experiment, shown on a schematic lateral view. Blue = dlPFC (cognitive load). Green = ACC (urgency/conflict). Orange = insula (visceral risk). Purple = visual cortex. Pink = TPJ (social cognition). Grey = amygdala and nucleus accumbens (subcortical — near-zero in TRIBE v2’s cortex-focused predictions).
The experiment: two paths, one brain
Here’s the interesting design choice. In the real world, scam messages reach victims through two channels simultaneously: the words (semantic content) and the visual presentation (a WhatsApp bubble, an SMS notification, a social media post with a scam image). TRIBE v2’s multimodal architecture lets us separate these and ask: does a scam hack your brain through what it says, or through how it looks?
I’m going to run the same scam messages through TRIBE v2 twice — via two different input paths — and compare the brain maps.
Path A — The text path (semantic processing). Feed the raw scam message as text. TRIBE v2 auto-converts text to speech via TTS (text-to-speech), runs WhisperX (a speech timing tool) to get word-level timestamps, then processes it through LLaMA 3.2-3B (language features) and Wav2Vec-BERT (audio features). This predicts how the brain would process the meaning of the message — the semantic manipulation, the emotional trigger words, the urgency framing.
Path B — The screenshot path (visual processing). Feed a realistic screenshot of the same message — rendered as it would actually appear in WhatsApp, an SMS inbox, or a social media feed. TRIBE v2 processes this through V-JEPA2 ViT-Giant (visual features). Important: V-JEPA2 processes pixels, not text — the words inside the image are never linguistically decoded in this path. This predicts how the brain would respond to the visual presentation of the message — the UI patterns, the notification styling, the visual structure that scammers exploit.
The comparison is the story. If both paths light up emotional regions, scammers are hitting you from two directions at once. If the text path shows stronger amygdala activation but the screenshot path shows stronger visual cortex activity, it means the words do the emotional manipulation while the visual framing provides the camouflage of legitimacy. That’s a fundamentally different attack surface.
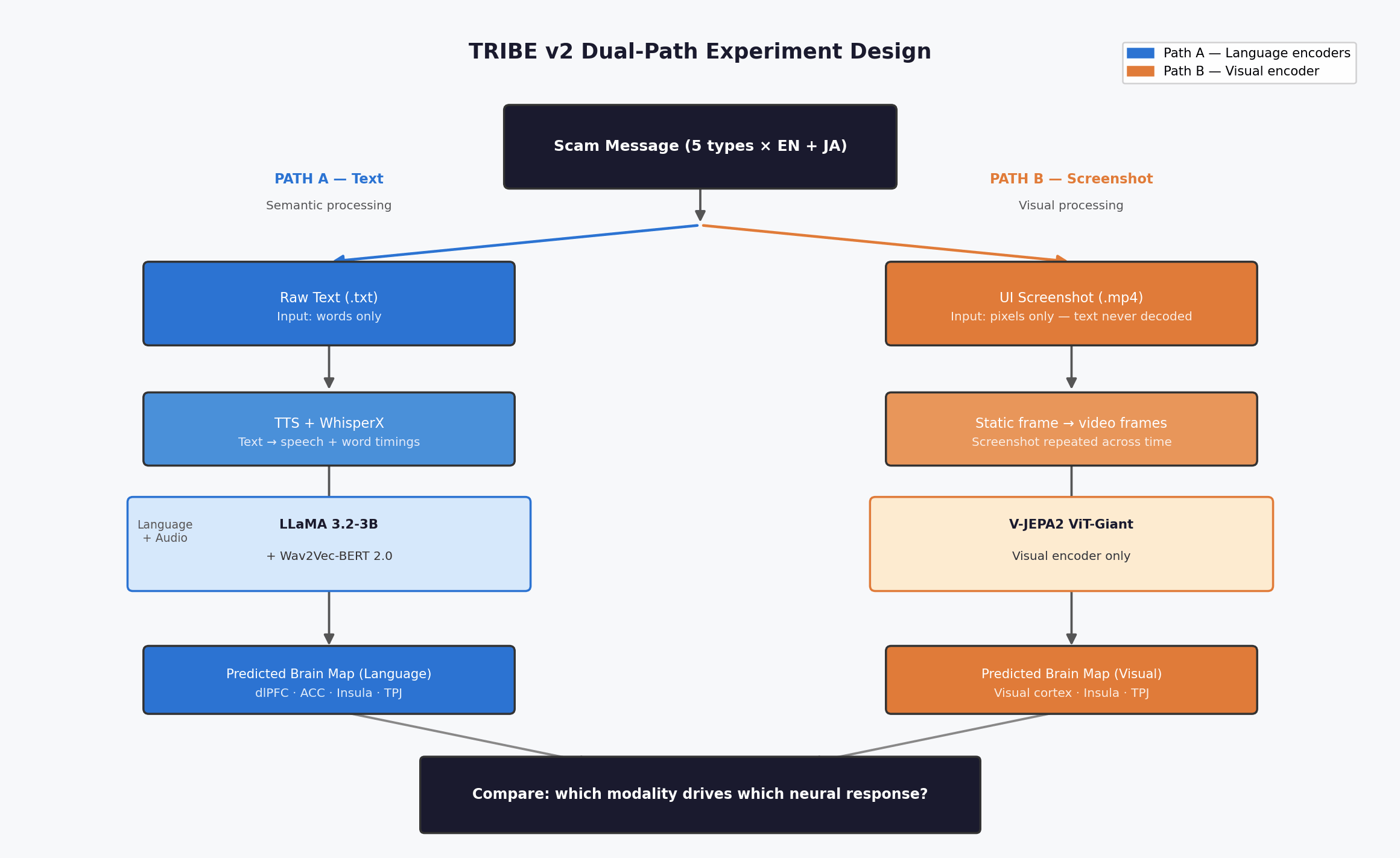 Figure 1: The dual-path design. Path A (blue) feeds raw text through language encoders — LLaMA + Wav2Vec-BERT. Path B (orange) feeds a rendered screenshot through the visual encoder — V-JEPA2 ViT-Giant, which processes pixels only and never reads the text inside the image. Both paths output predicted brain activation maps; the comparison between them is the experiment.
Figure 1: The dual-path design. Path A (blue) feeds raw text through language encoders — LLaMA + Wav2Vec-BERT. Path B (orange) feeds a rendered screenshot through the visual encoder — V-JEPA2 ViT-Giant, which processes pixels only and never reads the text inside the image. Both paths output predicted brain activation maps; the comparison between them is the experiment.
Input corpus:
A set of synthetic scam messages across four categories plus legitimate baselines, each prepared as both raw text and rendered screenshots. All messages in English and Japanese — because TRIBE v2 claims zero-shot cross-lingual generalization, and I want to test whether scam brain signatures are language-universal.
| Type | Message |
|---|---|
| Legitimate | “Your package has been shipped. Expected delivery: Thursday.” |
| Phishing | “URGENT: Your Amazon account has been compromised. Verify your identity immediately or your account will be permanently locked.” |
| Investment | “Exclusive crypto opportunity — 500% returns guaranteed in 30 days. Only 12 spots remaining. Act now.” |
| Fake Shop | “FLASH SALE: 90% OFF authentic Ray-Ban sunglasses! Today only. Free worldwide shipping.” |
| Pyramid Scheme | “Join our financial freedom network. Earn $5,000/month passive income by helping 3 friends discover the same opportunity.” |
For the screenshot path, each message gets rendered in a realistic messaging UI — WhatsApp-style chat bubbles, SMS notification layouts, social media post frames. The visual context matters: the same text in a WhatsApp bubble versus a plain email triggers different levels of trust and urgency.
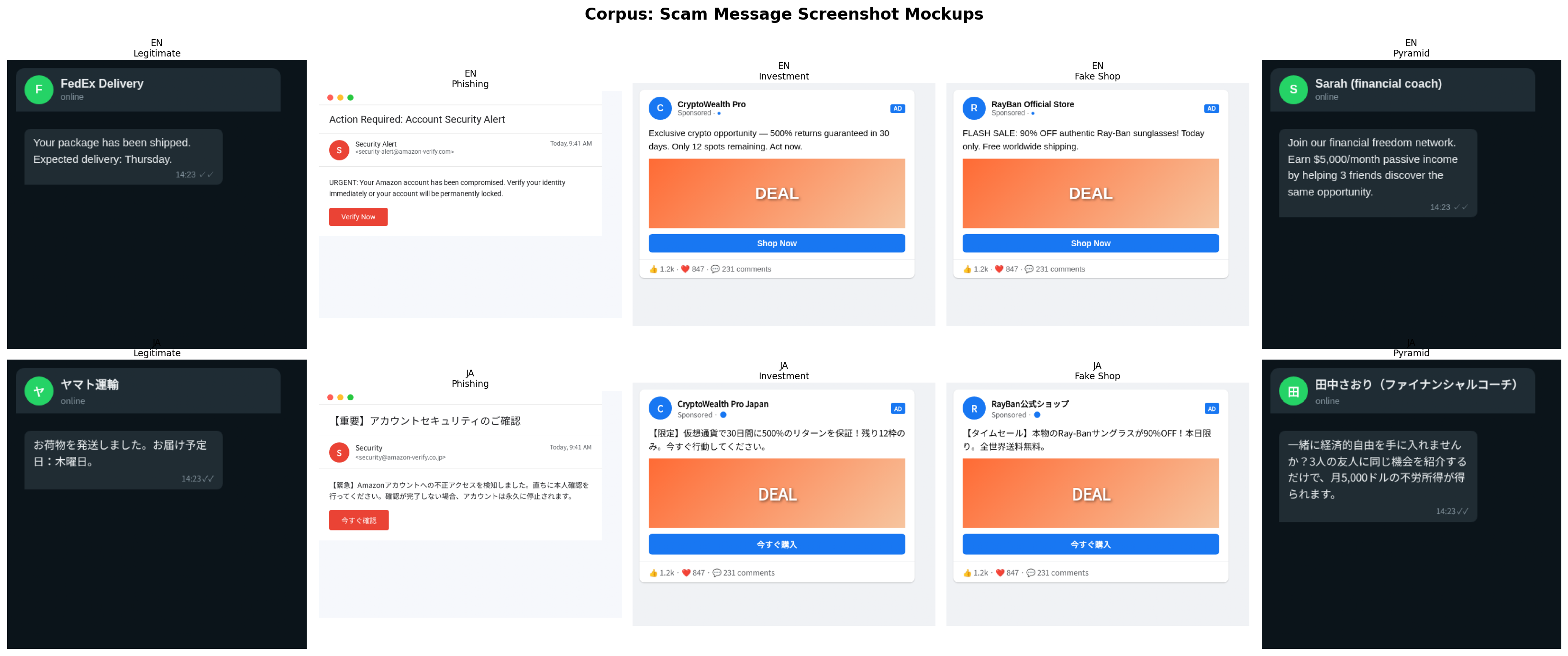 Figure 2: The 10 rendered stimuli — 5 message types × 2 languages (EN + JA). Each processed as both raw text (Path A) and screenshot (Path B), giving 20 inference runs total.
Figure 2: The 10 rendered stimuli — 5 message types × 2 languages (EN + JA). Each processed as both raw text (Path A) and screenshot (Path B), giving 20 inference runs total.
Process:
- Text path: Feed each message as raw text → TRIBE v2 auto-generates speech, extracts features via LLaMA + Wav2Vec-BERT → predict brain activation map
- Screenshot path: Feed a rendered screenshot of the same message → TRIBE v2 extracts features via V-JEPA2 (static image repeated across frames to simulate video input) → predict brain activation map
- Generate differential activation maps: scam minus legitimate baseline, separately for each path
- Compare activation in regions of interest: amygdala (fear), nucleus accumbens (reward), prefrontal cortex (cognitive load), anterior cingulate (conflict/urgency), insula (disgust/risk), visual cortex (visual processing)
- Cross-path comparison: overlay text-path and screenshot-path brain maps to identify which modality drives which neural response
- Repeat with Japanese translations to test cross-lingual consistency
What I expect to find:
The text path should show stronger predicted activation in language-processing and emotional regions — temporal cortex, amygdala, insula, prefrontal cortex. This is where the semantic manipulation is predicted to live: the fear, urgency, and reward signals that bypass rational evaluation. Whether TRIBE v2 captures subcortical regions like the amygdala depends on the model’s training coverage — cortex-focused models may not predict limbic responses reliably, which would itself be a finding worth reporting.
The screenshot path should show heavier visual cortex activation but also — and this is the interesting hypothesis — some emotional activation from the visual trust cues that scammers exploit. A message rendered in a WhatsApp bubble with a verified-looking profile picture should predict different brain responses than the same text in a suspicious-looking email. If TRIBE v2 picks up this visual-trust signal, it validates what scam researchers have known anecdotally: presentation matters as much as content.
Pyramid scheme messages should show the most ambiguous signature across both paths — closest to legitimate — which would explain why both humans and AI classifiers struggle most with this category.
And if the cross-lingual comparison shows similar brain signatures for the same scam translated into Japanese, that’s evidence that scam detection could use brain-signature features as language-agnostic signals.
Technical setup: TRIBE v2’s full encoder stack (LLaMA 3.2-3B + V-JEPA2 Giant + Wav2Vec-BERT) needs roughly 25GB of VRAM. I’ll be running this on Google Colab Pro with an A100 GPU (40GB), which handles all three encoders loaded simultaneously with room to spare. The screenshot path requires a minor note: V-JEPA2 expects video frames, so the static screenshot gets repeated across the temporal dimension to simulate video input.
 Figure: TRIBE v2 predicts brain responses across diverse regions. Solid lines show actual fMRI BOLD signals from a human subject watching a video; dashed lines show TRIBE v2’s predictions. The model captures temporal dynamics with high correlation (r = 0.77–0.85). Source: Meta AI Research.
Figure: TRIBE v2 predicts brain responses across diverse regions. Solid lines show actual fMRI BOLD signals from a human subject watching a video; dashed lines show TRIBE v2’s predictions. The model captures temporal dynamics with high correlation (r = 0.77–0.85). Source: Meta AI Research.
What this could mean for scam detection
If the experiment works, the implications go beyond an interesting visualization.
Manipulation potency scoring. Current scam detectors produce a binary output: scam or not. A brain-predictive model could add a dimension: how dangerous is this scam? A message that predicts strong prefrontal engagement — the brain working hard to evaluate something that doesn’t feel right — may be more insidious than one that triggers raw fear. Whether the primary signal turns out to be cortical (prefrontal, cingulate) or subcortical (amygdala, nucleus accumbens) depends on what the model actually predicts. Part 2 will show which regions actually light up.
Adversarial red-teaming. If you can predict which message variations produce the strongest brain hijacking response, you can generate the most dangerous possible scam variants and test whether your detection system catches them. Traditional adversarial testing mutates text randomly. This mutates text toward maximum predicted neural exploitation — a far more realistic threat model.
Verdict justification. Instead of telling a user “this is likely a scam,” imagine: “This message is designed to trigger your fear response while creating artificial time pressure to bypass your critical thinking.” That’s a fundamentally different user experience — you’re not just warning them, you’re vaccinating them against the technique.
Cross-language early warning. If a scam template predicts high emotional hijacking in English but low activation in Japanese, it likely won’t be effective (or prevalent) in Japan — and vice versa. This could predict which scam types will emerge in which markets before they appear in the training data.
Coming in Part 2
I’ll run the actual experiment — both paths — share the brain activation maps side by side, and find out whether the theory holds. Does a phishing message light up different brain regions than a shipping notification? Does a WhatsApp screenshot trigger different neural responses than the raw text? Is there a universal neural signature of a scam that works across languages and modalities? And does the pyramid scheme really look like a legitimate message to your brain?
The code, Colab notebook, and all visualizations will be open-sourced.
Glossary
fMRI (functional Magnetic Resonance Imaging) — A brain scanning technique that measures blood oxygen levels as a proxy for neural activity. When neurons fire, they demand more oxygen, and fMRI detects the resulting change in blood flow. It produces 3D maps of which brain regions are active at a given moment — but it’s slow (one scan every 1–2 seconds) and expensive.
Brain encoding model — A machine learning model trained to predict fMRI brain activity from a stimulus (text, audio, or video). Instead of putting a person in a scanner, you feed the stimulus to the model and it estimates what the brain would do. TRIBE v2 is this kind of model — trained on 451 hours of real fMRI data, then used to make predictions on new inputs.
Brain activation map / fMRI activation map — A visualization showing which parts of the brain are predicted to be more or less active in response to a specific stimulus. Warmer colours (red/yellow) = more activation. Cooler colours (blue) = less activation or suppression relative to baseline. In this experiment, all maps are predicted, not measured.
fsaverage5 cortical mesh — A standardized 3D model of the human brain surface used in neuroscience to compare data across individuals. “fsaverage” is an average brain; “5” refers to the resolution level (~20,484 surface points). TRIBE v2 outputs predictions at each of these ~20,000 points, which is how you get a full brain map.
Region of interest (ROI) — A specific brain area you’ve decided to measure in advance because you have a hypothesis about it. Rather than sifting through all 20,000+ brain points, you define ROIs (e.g., “prefrontal cortex”) and compute the average activation there. This experiment tracks seven ROIs: dlPFC, ACC, insula, visual cortex, TPJ, amygdala, and nucleus accumbens. The first five are cortical and extracted cleanly; amygdala and nucleus accumbens are subcortical and came out near-zero in TRIBE v2’s predictions (either a genuine finding or a model coverage limitation).
Hemodynamic response — The blood flow change that follows neural activity, which is what fMRI actually detects. It peaks about 5–6 seconds after the neuron fires, which is why TRIBE v2 offsets its predictions by 5 seconds — to account for this lag between “neuron fires” and “scanner detects it.”
Group-average prediction — TRIBE v2 was trained on data from 25 subjects. Its output is a prediction of how the average brain across those subjects would respond — not any individual’s brain. Individual brains vary significantly; the group average smooths this out and is often more reliable than any single subject’s scan.
dlPFC (dorsolateral prefrontal cortex) — The brain’s cognitive control engine. Handles working memory, goal maintenance, and conflict resolution — the mental work of evaluating something that doesn’t add up. When dlPFC fires hard, it means the brain is working to assess a situation critically. In this experiment, it’s the top-activated region for all four scam types via text, suggesting scam messages force cognitive engagement.
ACC (anterior cingulate cortex) — A brain region involved in detecting conflict between competing responses and processing urgency signals. If something feels wrong but you’re being pushed to act fast, the ACC is firing. It sits at the intersection of emotion and cognition.
Insula — A brain region deep in the cortex associated with interoception (sensing internal body states), disgust, and visceral risk signals. When something triggers a “gut feeling” of wrongness, the insula is often involved. In this experiment, the pyramid scheme screenshot produced the only positive insula response in the screenshot path.
Visual cortex — The primary region at the back of the brain that processes visual information — shapes, colours, motion, spatial layout. Expected to activate strongly for visual stimuli. Notably, it suppressed in the screenshot path for all scam types — suggesting familiar UI templates don’t produce visually distinctive patterns.
TPJ (temporo-parietal junction) — A brain region involved in theory of mind — the ability to model other people’s intentions and perspectives. Relevant for social manipulation (does the sender want something from me?). Shows up in investment and fake shop conditions in the text path.
Amygdala — A subcortical structure (deep in the brain, below the cortex) strongly associated with fear, threat detection, and emotional learning. Conventional wisdom says phishing messages “activate fear” — but in this experiment, amygdala values were near-zero. TRIBE v2 was trained primarily on cortical (surface) data, so its subcortical predictions may not be reliable.
Nucleus accumbens — A subcortical structure central to reward anticipation and dopamine-driven motivation. Expected to activate for investment scams (“500% returns”). Like the amygdala, came out near-zero here — same TRIBE v2 coverage caveat applies.
Text path vs screenshot path — The two input routes in this experiment. The text path feeds the raw message words to TRIBE v2’s language encoders (LLaMA + Wav2Vec-BERT), which process meaning. The screenshot path feeds a rendered image of the message to the visual encoder (V-JEPA2), which processes pixels — it never reads the words inside the image. They answer different questions about the same message.
Differential activation map — A brain map showing the difference between a scam condition and the legitimate baseline. Instead of “how does the brain respond to phishing?”, it shows “how does the brain respond to phishing differently than to a normal shipping notification?” Positive values = more activation for the scam; negative values = less.
Cross-language correlation (r) — A measure of how similar two brain maps are to each other, ranging from −1 (opposite) to +1 (identical). In this experiment, it compares English vs Japanese versions of the same scam type. Screenshot path r = 0.983–0.998 (near-identical). Text path r = 0.592–0.911 (correlated but with meaningful differences). The high screenshot correlation reflects that UI visual patterns are globally uniform.
TRIBE v2 is used under its CC BY-NC 4.0 license for non-commercial research. TRIBE v2 figures courtesy of Meta AI Research, from “A Foundation Model of Vision, Audition, and Language for In-Silico Neuroscience” (2025).