
Part 2 of 2 — The results. Part 1 covered the theory and experiment design.
TL;DR: I ran scam messages through TRIBE v2 — Meta’s brain-encoding model — via two paths: raw text (language encoder) and rendered screenshot (visual encoder). The language encoder predicts stronger prefrontal activation for scam text vs legitimate text, consistent across all four scam types and both English and Japanese. The visual encoder predicts lower visual cortex activation for scam screenshots than for the legitimate baseline — the scam UI doesn’t stand out visually. And the visual encoder’s brain maps are near-identical across English and Japanese (r = 0.98–0.99), while the language encoder’s maps vary more by language (r = 0.59–0.91). These are computational predictions, not real brain measurements — but the patterns are consistent enough to be worth taking seriously.
When Meta released TRIBE v2, I kept thinking about what it could mean for scam detection. This is me finally running that experiment — a personal research project, not a peer-reviewed study. Treat the findings as hypotheses worth questioning, not conclusions worth citing. If something here raises a doubt or suggests a better experiment, the comments are open.
Last time I set up an experiment using TRIBE v2 — Meta’s brain-encoding model — to predict what the human cortex might activate when processing a scam message versus a legitimate one. To be precise: TRIBE v2 doesn’t measure brains. It predicts group-average fMRI activation patterns based on a model trained on 451 hours of real fMRI data. Think of it as a computational proxy — useful for hypothesis generation at scale, not a substitute for putting people in a scanner.
Two input paths: feed the raw text through the language stack (LLaMA 3.2-3B + Wav2Vec-BERT), or feed a rendered screenshot of the same message through the visual encoder (V-JEPA2 ViT-Giant). Important distinction: these are different encoders seeing fundamentally different representations of the same content. Path A processes words. Path B processes pixels — it never reads the text inside the image. Two different questions about the same stimulus. I promised results. Here they are.
The Setup (Fast Version)
Five message types: a legitimate shipping notification as baseline, plus four scams — phishing (“Your Amazon account has been compromised”), investment (“500% returns guaranteed”), fake shop (“90% OFF Ray-Ban sunglasses”), and pyramid scheme (“Earn $5,000/month passive income”). Each rendered as both a plain text file and a realistic UI screenshot (WhatsApp chat bubble for SMS-style scams, social post frame for the others).
 The 10 rendered stimuli: 5 message types × 2 languages. Each processed as both raw text and screenshot.
The 10 rendered stimuli: 5 message types × 2 languages. Each processed as both raw text and screenshot.
Each pair ran through TRIBE v2’s dual-path inference on Colab Pro (A100 40GB). The model outputs a predicted fMRI activation surface on the fsaverage5 cortical mesh (a standard 3D brain surface model used across neuroscience research) — roughly 20,000 cortical vertices plus ~8,800 subcortical voxels (deep brain structures). For region-of-interest analysis I attempted seven pre-defined regions: dlPFC, ACC, insula, visual cortex, TPJ, amygdala, and nucleus accumbens. The first five are cortical and extracted cleanly via the Destrieux surface atlas (a standard brain region map that parcellates the cortex into named areas). Amygdala and nucleus accumbens are subcortical — their values came out near-zero across all conditions, which is either a genuine finding or a TRIBE v2 coverage limitation (the model was trained primarily on cortical fMRI). More on that in caveats. Then ran the whole corpus again in Japanese to test cross-lingual generalization.
What the Text Path Showed
The cleanest finding from the text path: dlPFC lights up for every scam type, without exception.
A note on terminology: Part 1 referred to “prefrontal cortex” and “ventromedial prefrontal cortex (vmPFC)” when predicting fake shop activation. The actual ROI extracted here is the dorsolateral prefrontal cortex (dlPFC) — a different subdivision. dlPFC handles working memory, goal maintenance, and conflict resolution. vmPFC handles value computation and reward evaluation. They’re neighbours, not synonyms. The experiment measured dlPFC; vmPFC was not separately extracted. That distinction matters for interpreting what “prefrontal activation” means in this context.
| Message Type | dlPFC | ACC | Insula | Visual Cortex | TPJ |
|---|---|---|---|---|---|
| Phishing (text) | +0.053 | +0.047 | +0.012 | +0.007 | +0.028 |
| Investment (text) | +0.061 | −0.007 | −0.005 | −0.106 | +0.047 |
| Fake Shop (text) | +0.074 | +0.023 | +0.023 | −0.036 | +0.039 |
| Pyramid Scheme (text) | +0.024 | −0.013 | −0.006 | −0.096 | +0.000 |
The dorsolateral prefrontal cortex is your rational evaluation engine — working memory, goal maintenance, conflict resolution. The model predicts it fires harder when reading scam text than any other ROI. Fake shop gets the highest dlPFC response at 0.074, followed by investment at 0.061, then phishing at 0.053. These aren’t random noise — they’re consistent with the hypothesis that high-manipulation text forces cognitive engagement.
The ACC (anterior cingulate cortex — conflict monitoring, urgency) co-activates with dlPFC for phishing (+0.047) and fake shop (+0.023), but goes slightly negative for investment and pyramid scheme. That’s interesting: the urgency framing in phishing and flash sale language triggers both conflict monitoring and rational evaluation simultaneously, which is exactly what makes them effective. Your brain notices the conflict and tries to reason through it — that’s the manipulation working as intended.
TPJ (temporo-parietal junction — theory of mind, social cognition) activates specifically for investment (+0.047) and fake shop (+0.039). The pyramid scheme TPJ is flat at 0.000. I expected pyramid to show the strongest TPJ signal given its explicit social network framing, but the model disagrees — or rather, predicts that the brain doesn’t engage social cognition for it. Make of that what you will.
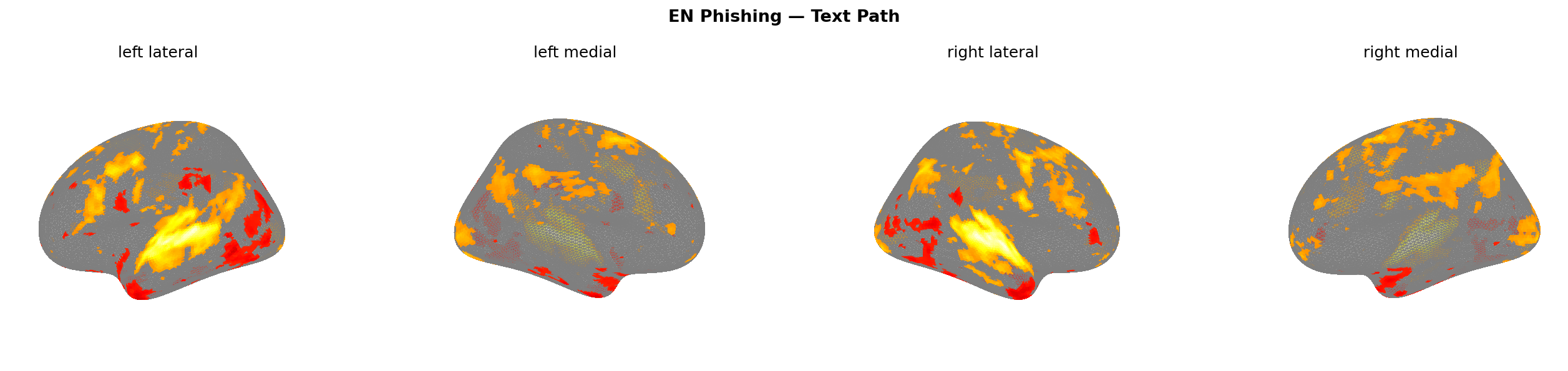
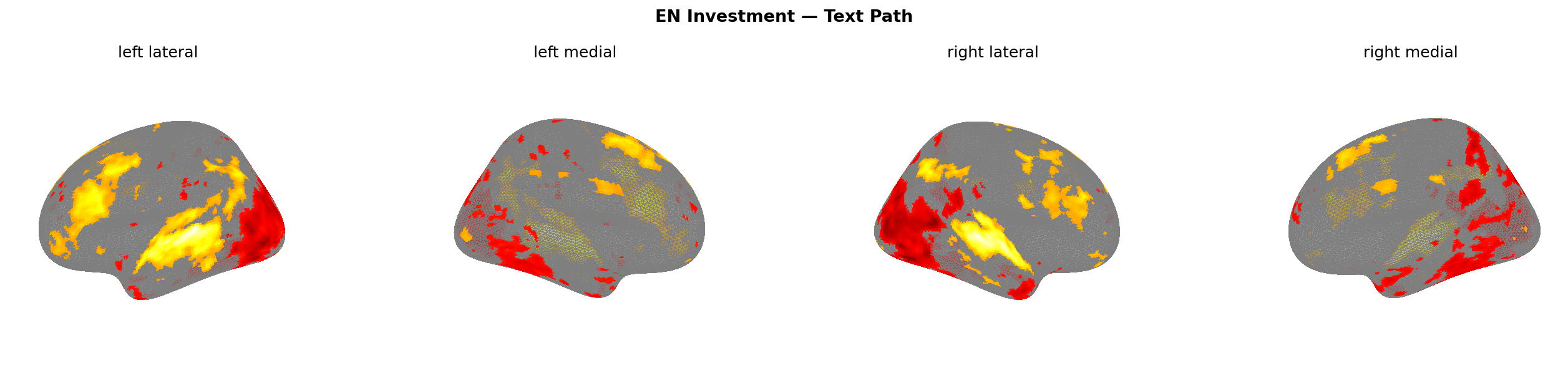
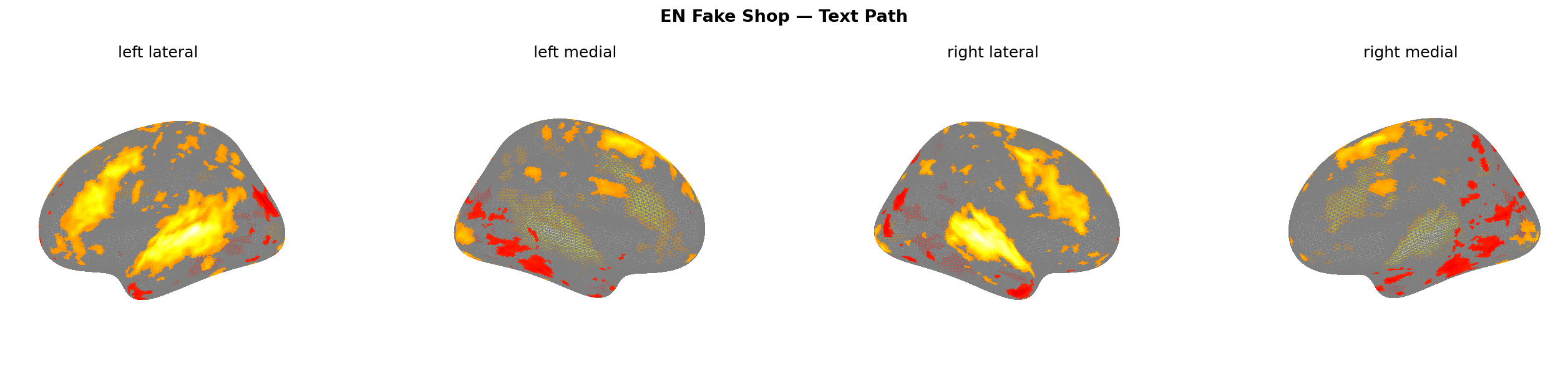
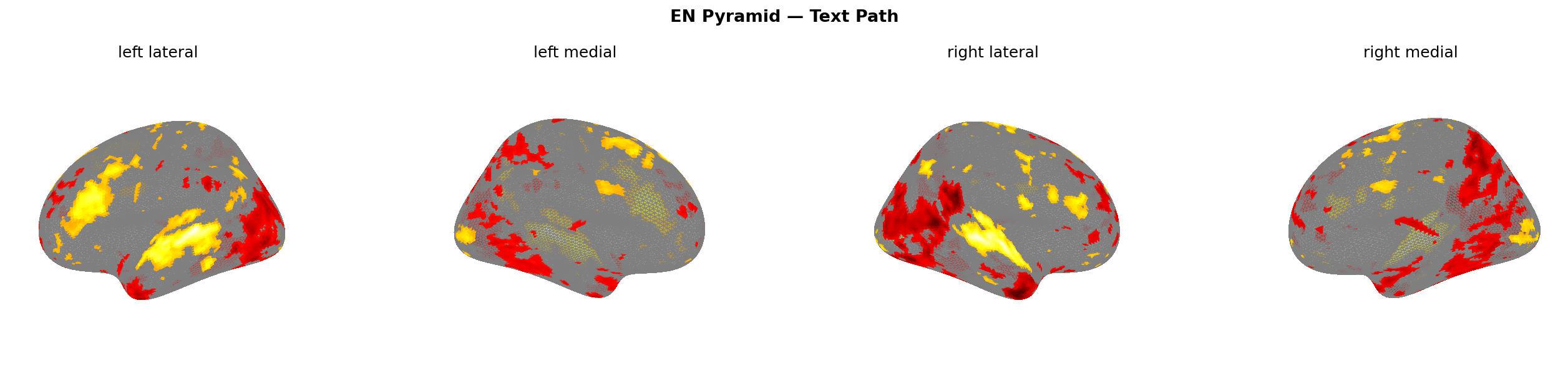
Figure 9: Predicted brain activation — text path, EN corpus. All four scam types. Warmer colours = higher predicted activation.
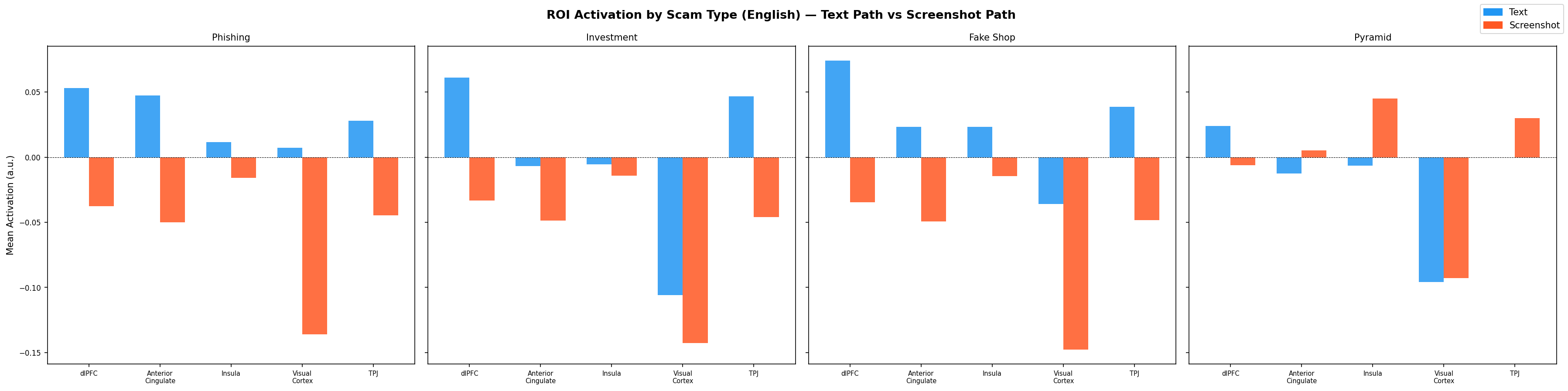 Figure 10: Mean activation per brain region — text path (blue) vs screenshot path (orange), EN corpus.
Figure 10: Mean activation per brain region — text path (blue) vs screenshot path (orange), EN corpus.
What the Screenshot Path Showed (The Surprise)
I expected the screenshot path to add to the text path signal — stack visual trust cues on top of semantic manipulation. That’s not what happened.
| Message Type | dlPFC | ACC | Insula | Visual Cortex | TPJ |
|---|---|---|---|---|---|
| Phishing (screenshot) | −0.038 | −0.050 | −0.016 | −0.136 | −0.045 |
| Investment (screenshot) | −0.033 | −0.049 | −0.014 | −0.143 | −0.046 |
| Fake Shop (screenshot) | −0.035 | −0.049 | −0.015 | −0.148 | −0.049 |
| Pyramid Scheme (screenshot) | −0.006 | +0.005 | +0.045 | −0.093 | +0.030 |
The screenshot path suppresses activation for three of the four scam types. dlPFC goes negative (−0.006 to −0.038). ACC goes negative for phishing, investment, and fake shop (−0.049 to −0.050) but flips slightly positive for pyramid (+0.005). And the visual cortex — the region you’d most expect to fire when processing a visual — gets hit the hardest across all conditions: −0.093 to −0.148.
That’s the counterintuitive result: showing the brain a WhatsApp screenshot reduces visual cortex activation relative to baseline.
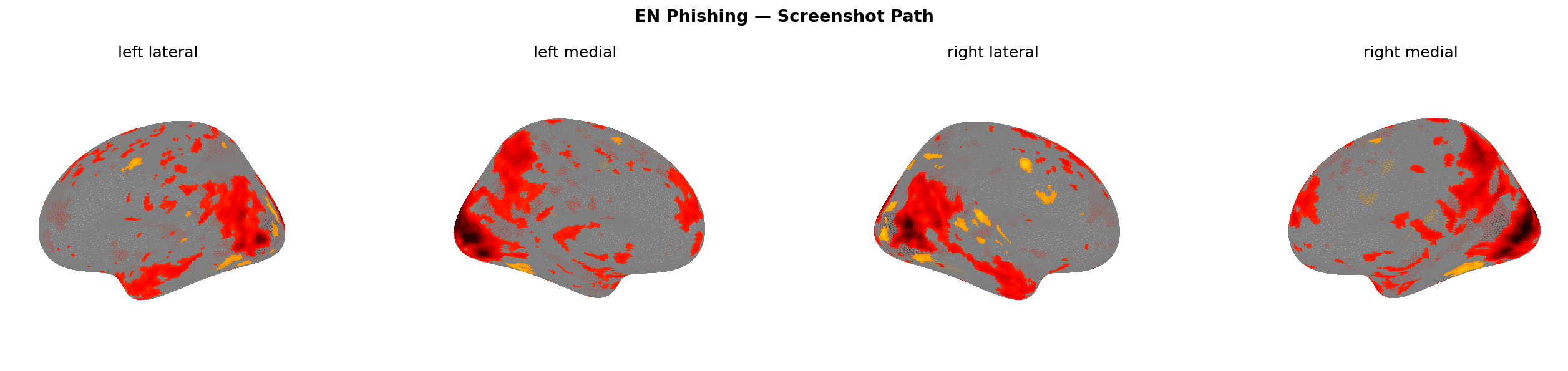
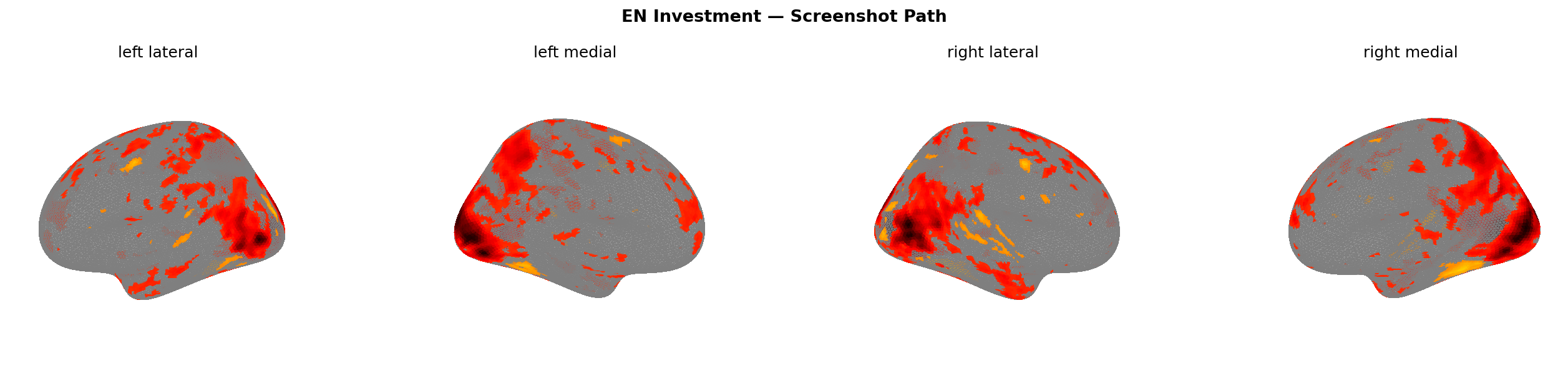
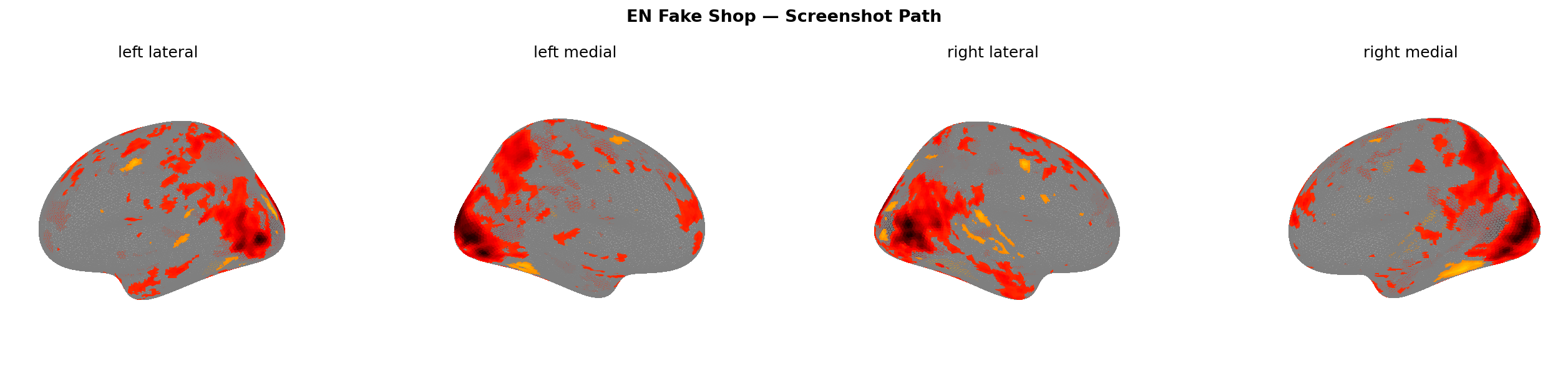
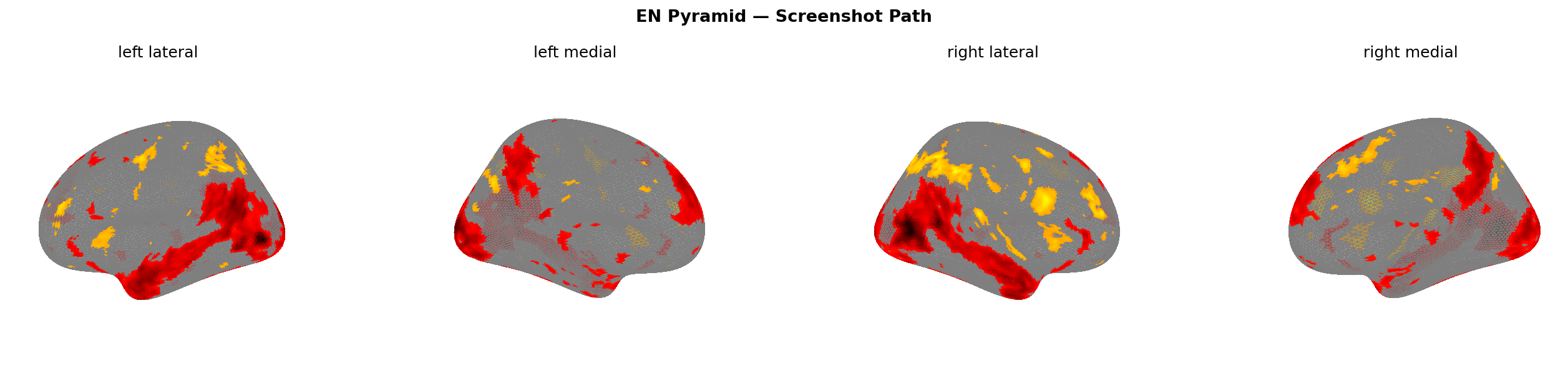
Figure 11: Predicted brain activation — screenshot path, EN corpus. Note the broad suppression (cooler colours) vs Figure 9.
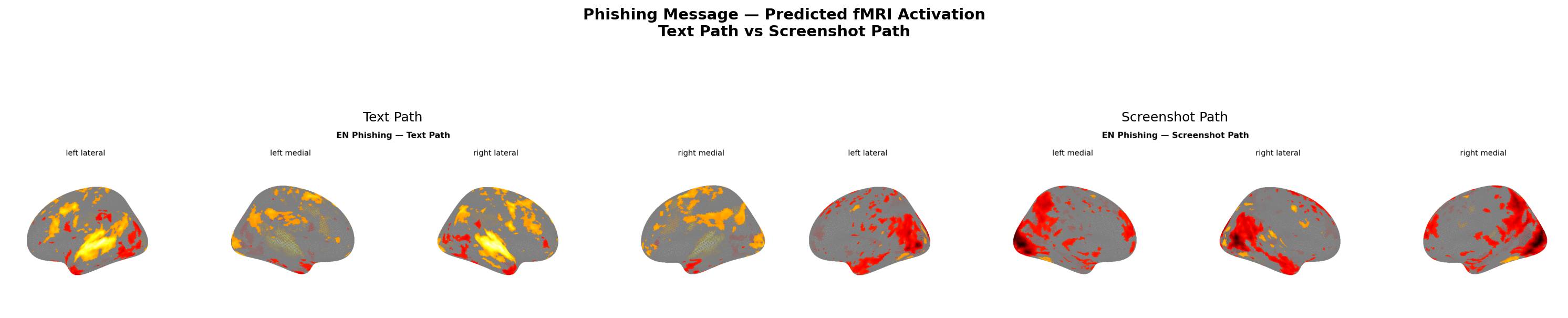 Figure 12: Same phishing message — text path (left) vs screenshot path (right). Note dlPFC activation on left, broad suppression on right.
Figure 12: Same phishing message — text path (left) vs screenshot path (right). Note dlPFC activation on left, broad suppression on right.
The one exception is the pyramid scheme insula response: +0.045, the only positive insula value in the screenshot path, and the largest insula value in the entire EN dataset. The insula encodes visceral risk signals — disgust, gut-level wrongness. Something about the visual presentation of the pyramid pitch specifically triggers that signal. The other scam types don’t. Whether that’s the particular visual structure I used for the rendering or something genuinely specific to multi-level recruitment imagery, I can’t say from n=1. But it’s the sharpest single anomaly in the data.
This directly contradicts what I expected in Part 1 — that pyramid scheme messages would show the most ambiguous signature, closest to legitimate. For the text path, that holds: pyramid scheme does show the lowest dlPFC response (+0.024, vs +0.074 for fake shop). But visually, it’s the most distinctive condition in the entire dataset. The prediction was half right: the words look almost legitimate; the visual presentation doesn’t.
Figure 13: Pyramid scheme screenshot (left) vs phishing screenshot (right). Insula activation visible in pyramid condition only.
Why the Visual Encoder Predicts Less Activation for Scam Screenshots
Worth being precise about what this result actually means before interpreting it.
Path B feeds a screenshot to V-JEPA2 — a video understanding model. V-JEPA2 processes pixels, not text. The words inside the WhatsApp bubble are never linguistically decoded in this path. The visual encoder is comparing: what does a scam screenshot look like versus what does a legitimate shipping notification screenshot look like — purely as visual patterns.
The result: TRIBE v2 predicts lower visual cortex activation for the scam screenshots than for the legitimate baseline. Not higher — lower. The scam UI, rendered in a familiar messaging interface, doesn’t produce a visually distinctive or novel pattern relative to a normal message. V-JEPA2 sees something that looks visually routine.
One interpretation: scam designers who wrap their content in standard UI templates (WhatsApp bubbles, SMS notification frames) are, deliberately or not, producing visual stimuli that a visual processing system treats as unremarkable. There’s no visual novelty for the encoder to flag. Whether this translates to reduced human attention is a hypothesis the data suggests but doesn’t prove — that would require actual eye-tracking or fMRI studies with real participants.
What the text path shows in contrast: the same scam content, stripped of UI context, predicted to drive dlPFC engagement. The words alone carry the manipulative signal. The UI wrapping, at least visually, does not add to it — it obscures it.
| ROI | Phishing (text) | Investment (text) | Fake Shop (text) | Pyramid (text) | Phishing (screenshot) | Investment (screenshot) | Fake Shop (screenshot) | Pyramid (screenshot) |
|---|---|---|---|---|---|---|---|---|
| dlPFC | +0.053 | +0.061 | +0.074 | +0.024 | −0.038 | −0.033 | −0.035 | −0.006 |
| ACC | +0.047 | −0.007 | +0.023 | −0.013 | −0.050 | −0.049 | −0.049 | +0.005 |
| Insula | +0.012 | −0.005 | +0.023 | −0.006 | −0.016 | −0.014 | −0.015 | +0.045 |
| Visual Cortex | +0.007 | −0.106 | −0.036 | −0.096 | −0.136 | −0.143 | −0.148 | −0.093 |
| TPJ | +0.028 | +0.047 | +0.039 | 0.000 | −0.045 | −0.046 | −0.049 | +0.030 |
Figure 14: ROI activation table — EN corpus. Bold = highest activation (text path) and strongest suppression (screenshot path).
The Cross-Language Finding (The Most Actionable Result)
TRIBE v2 claims zero-shot cross-lingual generalization (the ability to work in languages it was never explicitly trained on). The experiment tests that claim with an adversarial use case: do Japanese scam texts produce similar brain maps to English ones?
| Message Type | Text Path r | Screenshot Path r |
|---|---|---|
| Phishing | 0.604 | 0.994 |
| Investment | 0.911 | 0.998 |
| Fake Shop | 0.592 | 0.995 |
| Pyramid Scheme | 0.610 | 0.983 |
The text path cross-language correlation is moderate — 0.592 to 0.911. The screenshot path is near-perfect: 0.983 to 0.998 across all four scam types.
This makes sense structurally. Visual UI patterns — WhatsApp chat bubbles, sale banners, notification frames — are language-agnostic by design. The same visual template that works in English works in Japanese, Arabic, and Hindi because the UI conventions are global. The brain’s response to familiar UI structure is universal.
Text is different. Japanese and English activate overlapping but distinct language processing networks. The semantic content of “URGENT: your account has been compromised” in English versus “緊急:アカウントが侵害されました” in Japanese produces correlated but not identical predicted activation patterns — hence r ≈ 0.60 for phishing and fake shop.
One notable number: the Japanese phishing text path produces a dlPFC activation of 0.124 — more than double the English equivalent at 0.053. That’s the highest single dlPFC value in the entire experiment. Japanese phishing text triggers the strongest predicted prefrontal engagement of any condition tested. Whether that reflects something specific to Japanese-language urgency framing or a TRIBE v2 artifact from its training data distribution, I don’t know. But it’s worth flagging.
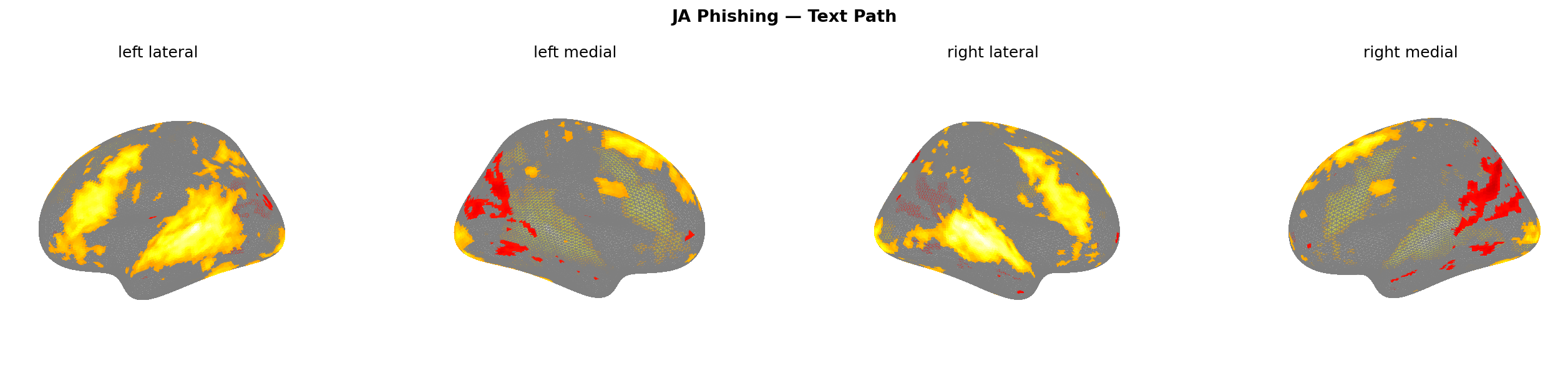
Figure 15: Phishing text path — EN (left) vs JA (right). r = 0.604. Divergence visible in left-hemisphere language regions.
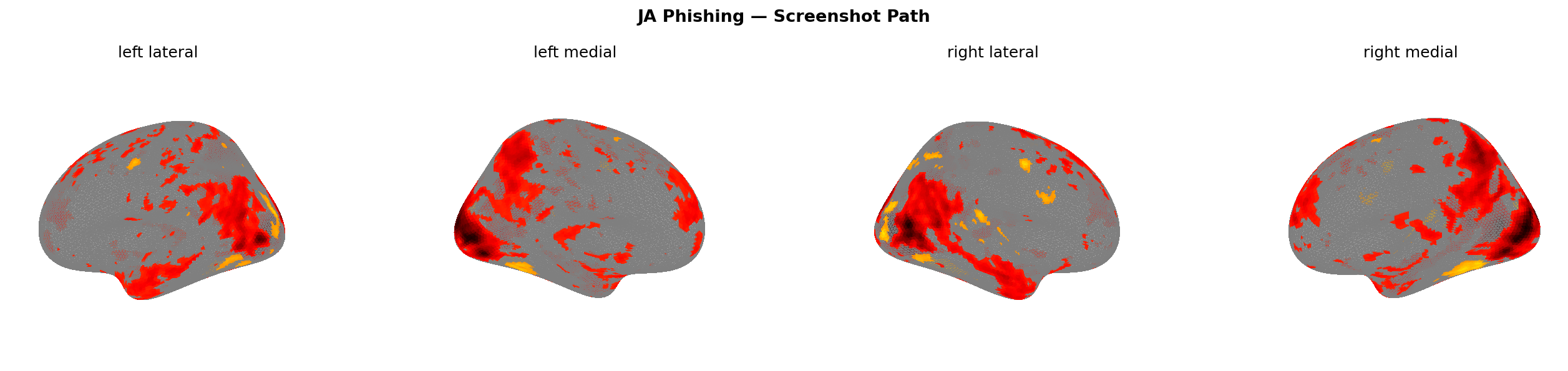
Figure 16: Phishing screenshot path — EN (left) vs JA (right). r = 0.994. Near-identical suppression pattern across both languages.
What This Means for Scam Detection
Three practical implications:
1. Text and visual signals carry different information — and current detectors only read one. NLP-based scam filters catch urgency words, too-good-to-be-true patterns, spoofed sender names. They operate on semantic content. What this experiment suggests — and it’s a hypothesis, not a proof — is that the visual encoding of a message carries a separate signal: how visually distinctive or routine the presentation looks. A scam wrapped in a standard UI template may be visually indistinguishable from a legitimate message even when the text is clearly manipulative. Detection systems that only analyse text are not seeing what the visual encoder sees.
2. Visual trust signals are language-universal attack surface. The r = 0.99 cross-language correlation on the screenshot path tells you that a scam template designed in one language ports to any other with near-zero friction. The visual attack is already global. Defending against it needs to be global too — which means UI-fingerprinting and brand impersonation detection that operates on visual structure, not just text content.
3. dlPFC suppression may be the key neural signature to look for. If the goal is to build models that predict susceptibility rather than just flag known patterns, the variable to track is probably prefrontal engagement — not amygdala activation (which, notably, showed near-zero values throughout this experiment). Fear isn’t the primary mechanism TRIBE v2 predicts. Cognitive load suppression is.
4. Audio-delivered scams may be the most dangerous channel — and this experiment accidentally suggests why. Path A is not purely a “text” path. TRIBE v2 converts the input text to speech via TTS before processing it through the language and audio encoders. That means Path A is actually predicting how the brain responds to a spoken version of the message — and it consistently outdrives Path B on prefrontal engagement across every scam type. This is directionally consistent with what scam researchers observe in the field: voice-based scams (vishing calls, WhatsApp audio notes, robocalls) tend to have higher victim conversion rates than text-based ones. The experiment’s Path A is synthetic speech with no emotional tone — a real scammer’s voice adds urgency, fear, and social pressure on top. If neutral TTS already predicts stronger cognitive engagement than a visual screenshot, real audio scams likely widen that gap further. Detection systems that don’t analyse audio are missing the highest-impact channel.
Caveats
This is an in-silico (computer simulation) experiment. TRIBE v2 is a model trained to predict group-average fMRI responses from a specific population under controlled conditions. It is not measuring real brain activity — it’s a proxy that correlates reasonably well with measured fMRI data in validation studies, but “reasonably well” is not “ground truth.”
The corpus is synthetic. I wrote these messages for the experiment; they are not drawn from real scam campaigns. Real scams are evolved and optimized; synthetic examples may under- or over-represent specific manipulation patterns.
The n is small: five message types, two languages, one model run. No statistical significance testing is meaningful here. The cross-language correlations and ROI values are observations, not generalizable findings. They suggest hypotheses worth testing properly.
The visual encoder is a video model running on still images. V-JEPA2 ViT-Giant (Meta’s video AI) was designed for video clips with motion and temporal dynamics. The screenshot path feeds it the same static frame repeated 16 times — a workaround, not an ideal input. A static image encoder like DINOv2 would be more appropriate for screenshots. That said, swapping it isn’t possible without retraining TRIBE v2 from scratch, since the whole model learned to map V-JEPA2 features to brain activations. Worth noting: a vision-language model (one that can actually read text inside images) would have been more powerful for screenshots, but would collapse the clean separation between Path A and Path B — the two paths would both “know” the words, and the comparison would lose its meaning.
What TRIBE v2 does well: provide a computational proxy for neural processing that can be applied at scale, without recruiting human subjects, and with consistent methodology across languages and modalities. That’s genuinely useful for hypothesis generation — which is what this experiment is.
What’s Next
The next step is rendering higher-fidelity screenshot mockups — the current ones are functional but basic. A more realistic WhatsApp UI with sender photos, read receipts, and conversation history context might shift the visual cortex suppression values meaningfully. I want to test whether increasing visual authenticity increases suppression (more familiar = less attention) or decreases it (more complex scene = more visual processing load).
I’m also planning to run the ROI extraction against TRIBE v2’s subcortical predictions — the near-zero amygdala and nucleus accumbens values in this experiment could be a true finding (scams don’t primarily operate through limbic fear/reward) or a limitation of the model’s cortical focus. Worth separating those two explanations.
The YouTube video covering this series is in progress. The experiment notebook — corpus creation, inference pipeline, visualization, ROI analysis — will be open-sourced once cleaned up. Drop a comment or reach out if you want early access.
When Meta released TRIBE v2, I kept asking myself: can a brain-encoding AI tell scam messages apart from legitimate ones? I finally ran the experiment. It turned into a two-part series, a Colab notebook, and more follow-up questions than answers — which is exactly what I was hoping for. If you’re a neuroscientist, an ML researcher, or someone who works in fraud detection and see something worth challenging here — I’d genuinely like to hear it.
Part 1 opened with: “What if you could watch, in real time, what a scam message does to someone’s brain?”
The honest answer after running this experiment: you can’t watch — not yet, not with this. What you can do is run a computational proxy that predicts what a population-average brain might do, and look for patterns in those predictions. The patterns were there. They weren’t always the patterns I expected. dlPFC, not amygdala. Suppression, not amplification. Near-perfect visual universality across languages.
That’s worth something. Not proof. A starting point.
Glossary
fMRI (functional Magnetic Resonance Imaging) — A brain scanning technique that measures blood oxygen levels as a proxy for neural activity. When neurons fire, they demand more oxygen, and fMRI detects the resulting change in blood flow. It produces 3D maps of which brain regions are active at a given moment — but it’s slow (one scan every 1–2 seconds) and expensive.
Brain encoding model — A machine learning model trained to predict fMRI brain activity from a stimulus (text, audio, or video). Instead of putting a person in a scanner, you feed the stimulus to the model and it estimates what the brain would do. TRIBE v2 is this kind of model — trained on 451 hours of real fMRI data, then used to make predictions on new inputs.
Brain activation map / fMRI activation map — A visualization showing which parts of the brain are predicted to be more or less active in response to a specific stimulus. Warmer colours (red/yellow) = more activation. Cooler colours (blue) = less activation or suppression relative to baseline. In this experiment, all maps are predicted, not measured.
fsaverage5 cortical mesh — A standardized 3D model of the human brain surface used in neuroscience to compare data across individuals. “fsaverage” is an average brain; “5” refers to the resolution level (~20,484 surface points). TRIBE v2 outputs predictions at each of these ~20,000 points, which is how you get a full brain map.
Region of interest (ROI) — A specific brain area you’ve decided to measure in advance because you have a hypothesis about it. Rather than sifting through all 20,000+ brain points, you define ROIs (e.g., “prefrontal cortex”) and compute the average activation there. This experiment uses seven ROIs: dlPFC, ACC, insula, visual cortex, TPJ, amygdala, and nucleus accumbens. The first five are cortical; amygdala and nucleus accumbens are subcortical and came out near-zero in TRIBE v2’s predictions.
Hemodynamic response — The blood flow change that follows neural activity, which is what fMRI actually detects. It peaks about 5–6 seconds after the neuron fires, which is why TRIBE v2 offsets its predictions by 5 seconds — to account for this lag between “neuron fires” and “scanner detects it.”
Group-average prediction — TRIBE v2 was trained on data from 25 subjects. Its output is a prediction of how the average brain across those subjects would respond — not any individual’s brain. Individual brains vary significantly; the group average smooths this out and is often more reliable than any single subject’s scan.
dlPFC (dorsolateral prefrontal cortex) — The brain’s cognitive control engine. Handles working memory, goal maintenance, and conflict resolution — the mental work of evaluating something that doesn’t add up. When dlPFC fires hard, it means the brain is working to assess a situation critically. Top-activated ROI for all four scam types in the text path of this experiment.
ACC (anterior cingulate cortex) — A brain region involved in detecting conflict between competing responses and processing urgency signals. If something feels wrong but you’re being pushed to act fast, the ACC is firing. Co-activates with dlPFC for phishing and fake shop text, but goes negative in the screenshot path for three of four scam types.
Insula — A brain region deep in the cortex associated with interoception (sensing internal body states), disgust, and visceral risk signals. When something triggers a “gut feeling” of wrongness, the insula is often involved. In this experiment, the pyramid scheme screenshot produced the only positive insula response in the screenshot path (+0.045) — the sharpest single anomaly in the dataset.
Visual cortex — The primary region at the back of the brain that processes visual information — shapes, colours, motion, spatial layout. Expected to activate strongly for visual stimuli. Counterintuitively, it suppressed in the screenshot path for all scam types (−0.093 to −0.148), suggesting familiar UI templates don’t produce visually distinctive patterns.
TPJ (temporo-parietal junction) — A brain region involved in theory of mind — the ability to model other people’s intentions and perspectives. Relevant for social manipulation (does the sender want something from me?). Shows up positively for investment (+0.047) and fake shop (+0.039) in the text path, but is flat for pyramid scheme.
Amygdala — A subcortical structure (deep in the brain, below the cortex) strongly associated with fear, threat detection, and emotional learning. Expected to activate for phishing — but near-zero throughout this experiment. TRIBE v2 was trained primarily on cortical (surface) data, so its subcortical predictions are unreliable. Fear may not be the primary cognitive mechanism here — or the model simply can’t measure it.
Nucleus accumbens — A subcortical structure central to reward anticipation and dopamine-driven motivation. Expected to activate for investment scams. Like the amygdala, came out near-zero — same TRIBE v2 coverage caveat applies.
Text path vs screenshot path — The two input routes in this experiment. The text path feeds the raw message words to TRIBE v2’s language encoders (LLaMA + Wav2Vec-BERT), which process meaning. The screenshot path feeds a rendered image of the message to the visual encoder (V-JEPA2), which processes pixels — it never reads the words inside the image. Two different questions about the same message, answered separately.
Differential activation map — A brain map showing the difference between a scam condition and the legitimate baseline. Instead of “how does the brain respond to phishing?”, it shows “how does the brain respond to phishing differently than to a normal shipping notification?” Positive values = more activation for the scam; negative values = less.
Cross-language correlation (r) — A measure of how similar two brain maps are to each other, ranging from −1 (opposite) to +1 (identical). Compares English vs Japanese versions of the same scam type. Screenshot path r = 0.983–0.998 (near-identical). Text path r = 0.592–0.911 (correlated but language-specific differences visible). The high screenshot correlation reflects that visual UI patterns are globally uniform regardless of language.
This experiment is independent personal research, unaffiliated with his employer. TRIBE v2 is used under CC BY-NC 4.0.